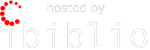Sanskrit, OCR, and SanskritOCR
Introduction
Almost every Greek and Latin text is freely available on the Internet, but the same can hardly be said for Sanskrit. However, Sanskrit's online presence has slowly increased over the past few years, and it is set to increase more and more in the years to come. This "online presence" is directly related to how many Sanskrit texts are available on the Internet. Texts, though, are of two kinds: scanned text, which exists as a collection of large images, and digitized text, which exists as a "text" file (just like this web page). Scanned text is OK, but it is often difficult to use. Digitized text, meanwhile, can be searched and processed more easily.
In order to quickly and easily turn scanned text into digitized text, we need a tool that can perform optical character recognition (or OCR for short). This page is a short guide to using OCR yourself. If you have a copy of a text that is not freely available on the web, please consider using an OCR program to spread it and make it more usable for everybody.
SanskritOCR
Only a few Devanagari OCR programs are available for public use. The most useful one is SanskritOCR. The software is difficult to find these days, but a few copies still survive on the web. You can download a copy of the software by clicking the link below:
Click here to download SanskritOCR.
Once you've installed and run SanskritOCR, you might notice that half of the program's menus and options are in German, which can make the program difficult to use. This guide is here to help you navigate these German menus and use the program as intended.
The homepage for SanskritOCR can be found here. The program was created by Dr. Oliver Hellwig, who is still developing it.
Using SanskritOCR
Creating a new project
Before you can start processing a text, you need to create and save a new project file. You can do so by clicking either File -> New Document or the white page button:

Save the file in the .sat (Stapel-Datei) format. You must save before you start OCR.
Now that you have your project space set up, it's time to bring in some material to process.
Importing files
You can import files either by scanning directly into the program or using saved images on your computer. I only have experience with using saved images, so I will describe that here. To load any number of image files, select File -> Open Image Files. You can import any number of image files at once. The program, however, recognizes only three image formats: .bmp, .jpg, and .png.
Your imported files will be listed in the Tools window. Use this window to view the different pages in your project.
If you do not see the Tools window anywhere, click Ansicht -> Werkzeugfenster to display it.
Preparing the image
You can rotate the image by 90 degree increments:
Do not worry if your image is slightly tilted. SanskritOCR will still be able to read it.
Once your image has the right orientation, you must mark the Devanagari portions of the image so that SanskritOCR will be able to scan more effectively. You are required to do this; SanskritOCR will not let you proceed if you do not. To do so, click the markup tool:

Using this tool, click and drag on the document to create boxes. If your image is at an uncomfortable size, you can use the zoom tools to adjust the image:
If the page consists only of Devanagari, you can put everything in one large box:

But otherwise, it's best to draw multiple boxes around the separate blocks of Devanagari:

Your text output will be presented in the order in which the boxes are numbered. You can use the tools next to the markup tool to delete and renumber the boxes in the image. You can also drag the edges of a box to better fit the text.
Cleaning and scanning
Before the scanning begins, you are required to clean the image. To do so, click the Clean image tool:

SanskritOCR will automatically clean, realign, and pre-process your text:

All that's left is the final scan, which you can run by clicking the Start recognition tool:

Results will depend on the quality of your scan. In the best case, the text is represented perfectly. In the worst, odd or unlikely combinations will appear. If the scanned text is faded, patchy, blurry, or so on, complete gibberish could be the result as well.
Watch out for gray boxes, which mark areas that could not be processed. Using more and smaller boxes in your markup may help. Oddly enough, you can also try using fewer and larger boxes.
Saving, processing, and using your output
The output from the scan cannot be saved directly. To copy your output to your computer's clipboard, click Recognised text -> --> Clipboard. For general-purpose processing, leave the Transcription mode on program transcription. The Range box will likely be grayed out. Click OK, then click OK again to close the dialog box that pops up.
Your text can now be pasted into a separate file, where it can be saved. Try pasting it in your favorite text program. If you do, you will probably get data like this:
kï¸catkåntåvirahagu?½å svådhikåråtpramattaµ ¸åpenåstaºgamitamadvimå var¹abhogye½a bhartuµ / yak¹a¸cadh÷?ï janakatanayåsnånapu½yodake¹u snigdhacchåyåtaru¹u vasatiº råmagiryå¸rame¹u // 1 //
You must process the text one more time. To do so, you can use the Sanscript tool provided on this site. Set your input scheme to SanskritOCR, and set your output scheme to whatever you like.
Your final product may still have artifacts or strange characters from SanskritOCR's raw output. Certain vowels or consonant groups may have been converted in odd ways. For these and many other reasons, proofreading is very important!
Now you have some raw text! Feel free to format and use this text however you like. If you have made a clean copy of the text, I encourage you to share it with sites like Sanskrit Documents or GRETIL so that people all over the world can have access to the fruits of your labor.
Common Questions
How do I save my project?
SanskritOCR saves automatically. You can just close the program when you're done. Your work will also be saved if SanskritOCR crashes. If SanskritOCR freezes or starts acting strangely, don't be afraid to close the program and start it up again.
My results are terrible! What am I doing wrong?
Use large grayscale images. If your image is not grayscale already, SanskritOCR will convert it for you, but this conversion seems to severely affect program output.
Can I process more than one page at a time?
No, unfortunately.
I have an image file that SanskritOCR does not recognize. What should I do?
Use an image processing program to change the file format. Irfanview is a good choice: it's lightweight, fast, free, and extremely powerful.
I have a PDF/TIFF/DJVU file that I would like to split into separate pages. How can I do this?
As before, use an image processing program to split the file up. Irfanview does not have much support for these files built-in, but if you download some plugins the program will be able to handle all of these file types. If you are using Irfanview, try opening your file and selecting
View -> Multipage images -> Extract all pages.Is SanskritOCR still under development?
Yes. Dr. Hellwig is working specifically on Hindi OCR, but the software will likely be able to deal with Sanskrit as well. The official website for SanskritOCR can be found here. The site mentions a
major relaunch
for the program, but there is no date provided.
If you have more questions, you can try emailing Dr. Hellwig.